Notes on Diffusion Models
以 DDPM 为代表的生成扩散模型在图像生成等领域上具有良好的效果, 并在学AI的文盲们面前小小地展示了一点数学功底的作用.
然而, 笔者读到的几乎所有扩散模型的教程都生硬地打着各种比喻, 提供了远超必须的直观性, 而完全失去了对其后数学动机的介绍. 即, 这样一个乍一看很陌生的过程是如何在保持数学上的有效性时被想到的.
因此, 本文希望展现这一想法可能的一种来龙去脉, 让读者感受到"想到这些关键点, 我也能发现 DDPM".
问题定义
考虑一个未知的
例如, 我们有一些关于猫的图像(每张图像可以用高度乘宽度乘通道数个实数来唯一表达), 它们属于一个
一个小小的提示是我们的答案将依赖于以下假设:
从流模型开始
感谢mt19937这类随机数发生器, 我们可以轻松地得到任意区间
例如, 我们可以首先根据
我们的问题不过是寻找一个高级的随机数发生器, 来根据
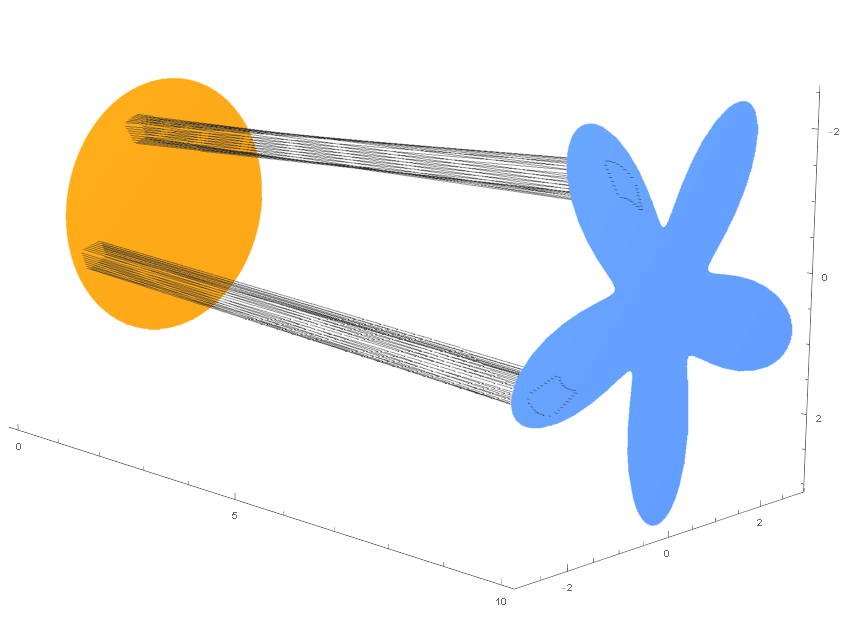
现代神经网络一般被看作一个参数化的函数
- 容易求逆
- 雅可比行列式
便于计算(例如, 恒定为 ) - 具有足够的表达力, 以捕捉复杂分布的映射关系
容易想象, 前面这两点往往要求
以NICE: Non-linear Independent Components Estimation为典型的许多工作都较好地实现了上面三项要求. 它们往往使用多个堆叠的简单变换来表示
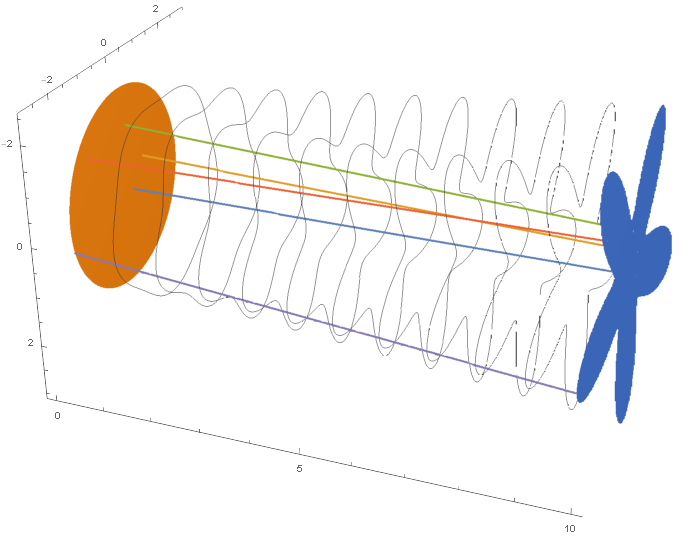
其中,
设
容易看出, 在给定
而
因此,
ODE描述的流模型
不难想到, NICE中使用的函数, 其堆叠层数越多, 所具有的非线性拟合能力就越强. 然而另一方面, 每个被堆叠的层可选取的函数形式都太受限了, 也带有过多的人工设计的痕迹, 因而整个堆叠所能等价的函数只是函数空间中的一小部分.
一个自然的想法是, 取堆叠层数

稍有物理背景的读者可能会看出, 对一个量连续施加上面所说的无穷小变换, 可以看作这个量在随着时间不停地演化.
因此我们在前述极限下, 将层数
此时, 我们实现了前面的要求. 这一过程对于
这一问题有非常清晰的物理意义, 即将
SDE描述的流模型
在上文中, 我们设想了使用ODE来代替人工设计的可逆变换, 搭建源分布和目标分布之间的桥梁. 然而ODE并不是最广的那一类变换的描述方法. 与本文第一张图片类似, 在ODE中, 一组样本在时间中的轨迹构成了"流管"的边界, "流管"中的样本不会流动到"流管"外面去.
然而, 这一性质在我们的目的中其实并不需要满足. 流管内外的样本完全可以随机交换, 只要从统计上说流管的流量是守恒的即可. 换句话说, 前面的ODE只需要负责描述概率密度的"流动", 而无需对单个样本的采样过程负责. 因此前述的ODE可以进一步扩展为SDE来描述具体样本的采样过程, 加上一个随机项, 写为
Fokker-Planck 方程
在给定单样本演化所遵从的以上SDE时, 我们也可以写出其概率密度所要遵从的方程, 即所谓 Fokker-Planck 方程:
为了推导 F-P 方程, 我们可以先写出它的传播子. 即, 若
由于
可以知道
因此在任意给定的
以上表达式都是在
而
因此可以凑出一个关于
用此式取代掉上面的积分中
或者, 更一般地, 对于高维情况, 有
可以看出, 上式右边的第一项表示在
概率流ODE
事实上, 对于同一个具体的F-P方程, 有一族SDE可以与它对应; 同时还有一个ODE(称作概率流 ODE)给出的概率密度对时间的偏导数与之相同; 这一ODE可以看作前面的SDE族中
例如, 对于任意
因此(在已知原有的概率密度
在
SDE的逆过程
SDE和ODE有一个显著的不同. 在时间反向流动时, ODE描述的过程可以完美地变成其逆过程:
而从一组遵从
具体来说, 考虑
不难发现, 其对应的概率流ODE正好是
因此可以知道, 这一过程正是SDE的逆过程.
ODE/SDE流模型的实现
至此我们已经讨论了流模型的无限层极限, 并使用ODE/SDE刻画了这一极限.
回到我们待解决的问题中来. 我们面前有一些从
对于前一步, 我们可以比较轻易地写出ODE/SDE来实现这一变换.
ODE流模型示例: PFGM
对于ODE而言, Poisson Flow Generative Models就是一个良好的例子. 考虑在样本所在的空间上再加一维

SDE流模型示例: DDPM
对于SDE而言, 只需要让样本的演化等价于
此时, 正向过程的SDE形式完全不包含和具体样本相关的信息, 同一个SDE可以保证任何
由于
因此在
由于上式需要对任意
在本小节开头给出的SDE形式下, 这一损失函数可以进一步改写. 容易发现,
简单进行一下重参数化, 即定义新的待学习函数
- 预测噪声的形式模糊了SDE描述的流模型这一远为通用的思维框架
- 目前所得这一形式的损失函数训练效果更好
- 加噪-降噪的形式暗示我们生成过程是移除噪声的过程; 从这一观点出发无法看到由概率流ODE诱导的一族逆向SDE过程的存在, 更不能看到 Schrödinger Bridge 方法等更广泛的生成模型的世界.
此时, 假设我们已经得到了
概率流ODE作为一个噪声向量到目标分布的确定性变换还允许我们对噪声向量插值, 以获得两个样本的在分布中的混合结果(例如, 符合逻辑的图片插值, 显然不能直接对同一位置的像素颜色插值, 这样生成的图片不在分布中).
扩展
条件生成模型
在 DDPM 的基础上, 我们可以依据拟合好的
// TODO: 写完DDPM相关就失去了写的兴趣, 有空的时候再回来写吧~
- latent diffusion
- 条件生成模型
- Schrödinger Bridge
- ...
- 1.本文中直接使用某个分布的概率密度的函数名来称呼该分布.例如,h(x)中的样本可以理解为一组遵从h(x)概率密度采样得到的样本 ↩︎
- 2.考虑到单个实数的测度为0,我们就不考虑开闭区间的问题了. ↩︎
- 3.真正的正态分布发生器不是这样工作的,这只是一个理论上可行的方案,因为这个CDF的逆没有解析式. ↩︎
- 4.有的人喜欢说流模型的训练是在做最大似然估计.然而,描述两个分布是否接近有许多种度量,最大化对数似然只是在你使用KL散度时的等价目标;没有任何实现难度之外的理由阻止你使用JS散度或者Wasserstein距离之类的玩意,此时的目标函数自然不等价于对数似然.顺便一提,我很讨厌散度这个名字,因为它令人错误地想到矢量分析,翻译为分歧度也许会更好. ↩︎
- 5.见这里 ↩︎
- 6.一个逆向的推导见这里 ↩︎